ページランクとは、あるウェブページが訪問される確率を数値計算(パワー法)で算出したもので、グーグルの特許です
ページランクとは=確率です
ページランクとは、グーグル独自のウェブページの重要性を決定する尺度です。ウェブ上における他ページからのリンクを学術論文における引用と同等視することがその根本発想です。 即ち、より多く引用されている論文は、有意義であるはずだとの発想なのです。
このような発想は、グーグル創設者の論文に明記されているように従来からあったのですが、決定的なのは、重要ではない(=ページランクの低い)多くのウェブページからリンクされているウェブページよりも、重要である(=ページランクの高い)ウェブページからリンクされているウェブページの方が、ページランクが高くなるように設計されているという点です。(下記の簡単な例を見てください。)
ページランクは、グーグルが、検索順位を決定する場合における、いわばウェブページの属性であり、直接的にページランク順に検索順位が決定されるという性格のものではありません。 (グーグルが創設された当初は、完全にページランクどおりに検索順位が決定されていました。これは、ページランクがウェブページが訪問される確率を意味するからですが、現在では、他の多くの順位決定要素が加味されています)
なお、ページランクは、発明者、Larry Page、特許権帰属者、スタンフォード大学とする特許であり、ウェブ上で、その算出原理・概要を誰でも知ることができます。
ちなみに、ページランクのページ=pageは、webpageのページではなく、Lawrence Page のページです。つまり、「ページ(さんがつけた)ランク」=「ページランク」です。もう一人のグーグル共同創設者セルゲイ・ブリンは、私の記憶では、20歳で、スタンフォード大学の博士課程に入学していますので、数学の天才といえるでしょうね。
このページでは、上記リンク先の公開文書に基づき、英語を読むのに非常な苦痛を感じる方、又は、英文が読めても初歩的な数学をご存知ないためにその内容が理解しがたい方のために、ページランクの算出原理とそれを実際に適用する場合のランダムサーファーモデルについて可能な限り平易に解説しました。これ以上、分かりやすい解説は、英文を含めてウェブ上には、存在しないと自負します。(ランダムサーファーとは、ネットサーフィンをしている方のことです。)
ただし、ページランクの正確な理解は、数学の知識なしでは、絶対に不可能であることをご理解ください。少なくとも、線形代数の基礎知識が必要です
数学なしのページランクの解説
ウェブ世界が、次のようにたった3つのウェブページから構成されていると仮定します。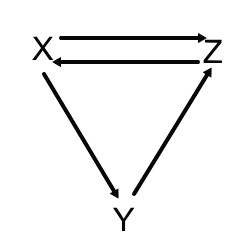
このリンク関係は、次のような簡単な数式で記述しえます。
下記の式の左のX・Y・Zのそれぞれのウェブページについて、右側の式で他のページとの関係を示すと考えてください。
①X=Z Xは、Zの発する唯一のリンクを受けています。
②Y=X/2 Yは、Xの発する2つのリンクのうち、ひとつを受けています。
③Z=X/2+Y Zは、Xの発する2つのリンクのうちひとつを受け、かつ、Yの発する唯一のリンクを受けています
答えの値は、ひとつに決まりません。しかし、答えの値の比は、でます。つまり、X:Y:Z=2:1:2です。
合計を1にするように、比の値を求めれば、X:Y:Z=0.4:0.2:0.4です。これがページランクの算出原理です。
そして、合計が1であることは、ページランクが確率であることを意味しています。
即ち、ウェブページが訪問される確率に応じて検索順位を決定するというのが、グーグル設立時の根本発想であったのです。
そして、注意していただきたいのは、上の例ですら、Xは、ひとつのバックリンクしかないのに、2つのバックリンクをもらっているZと同じ数値になっている点です。 これは、Xが(高い評価の)Zからリンクされているからなのです。これが、ページランクの計算原理の決定的に重要な点です。また、実際の数値計算は、パワー法と呼ばれる反復計算で算出されます